Benchmarking node in cluster mode.

My name is Ukagha Promise, I am a full-stack engineer and a technical writer. I am passionate about solving problems by building software.
Introduction
In the first article of this series, I explained how to improve node's performance using clustering. I explained why the ideal number of child_processes a dev should fork, should be equal to the number of cores of the CPU or lesser.
Performance metrics
I will go into greater detail about why increasing the number of child_processes will slow down code execution, using the loadtest module.
The loadtest module, allows you to simulate a specified number of concurrent connections to your API so that you can measure its performance.
First off, install the loadtest module globally using npm i -g loadtest
Let's start running our benchmarks and see why we get diminishing returns anytime there is an increase in the number of child_processes.
The number of threads was set to one, for easier observation of the result.
process.env.UV_THREADPOOL_SIZE = 1
const cluster = require('cluster')
const clusterCounter = 1
if(cluster.isMaster){
for(let i=0; i < clusterCounter; i++){
cluster.fork()
}
}else{
const express = require('express')
const app = express()
const crypto = require('crypto')
app.get('/', (req,res) => {
crypto.pbkdf2('a', 'b', 100000, 512, 'sha512', () => {
res.send('Hello from pbkdf2')
})
crypto.pbkdf2('a', 'b', 100000, 512, 'sha512', () => {
res.send('Hello from pbkdf2')
})
})
const port = 5000
app.listen(port, () => console.log(`server started on port ${port}`))
}
While following along with the example above, your processing time might be different, because of the specs of your PC and what you might be running in the background.
We will benchmark using the code snippet. The pbkdf2 hashing method will be used to mirror a processing-heavy task.
Keywords:
-n: number of requests-c: number of concurrency, it indicates how many request will be executed at oncemean latency: this the time taken to process the first requestlongest request: this is usually the set of request that were processed last- " 50%": This is the median time taken to process requests
Test 1
Open a terminal window and run loadtest http://localhost:5000/ -n 1 -c 1
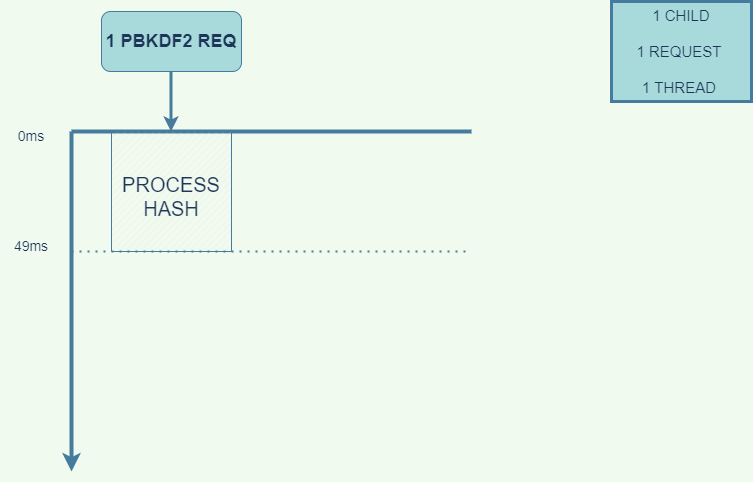
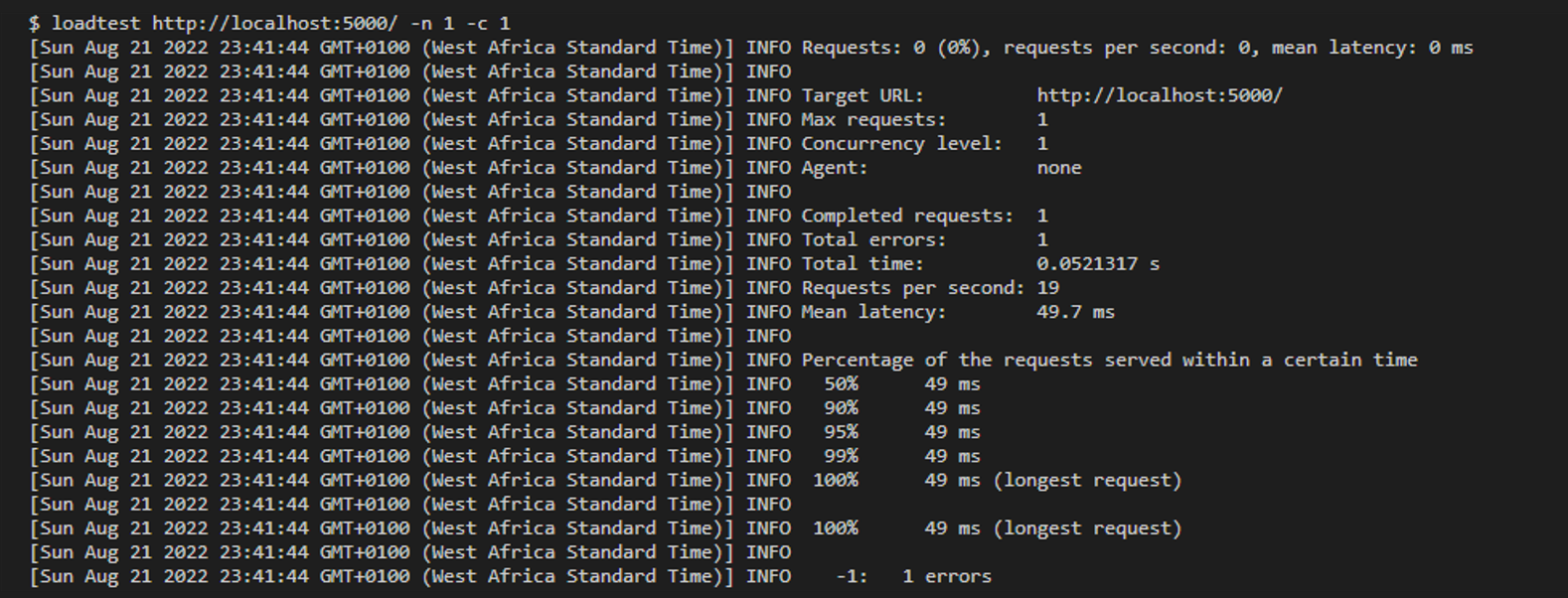 It took 49 ms to run a single request.
It took 49 ms to run a single request.
Test 2
Increase the number of requests and concurrency to 2.
Run loadtest http://localhost:5000/ -n 2 -c 2
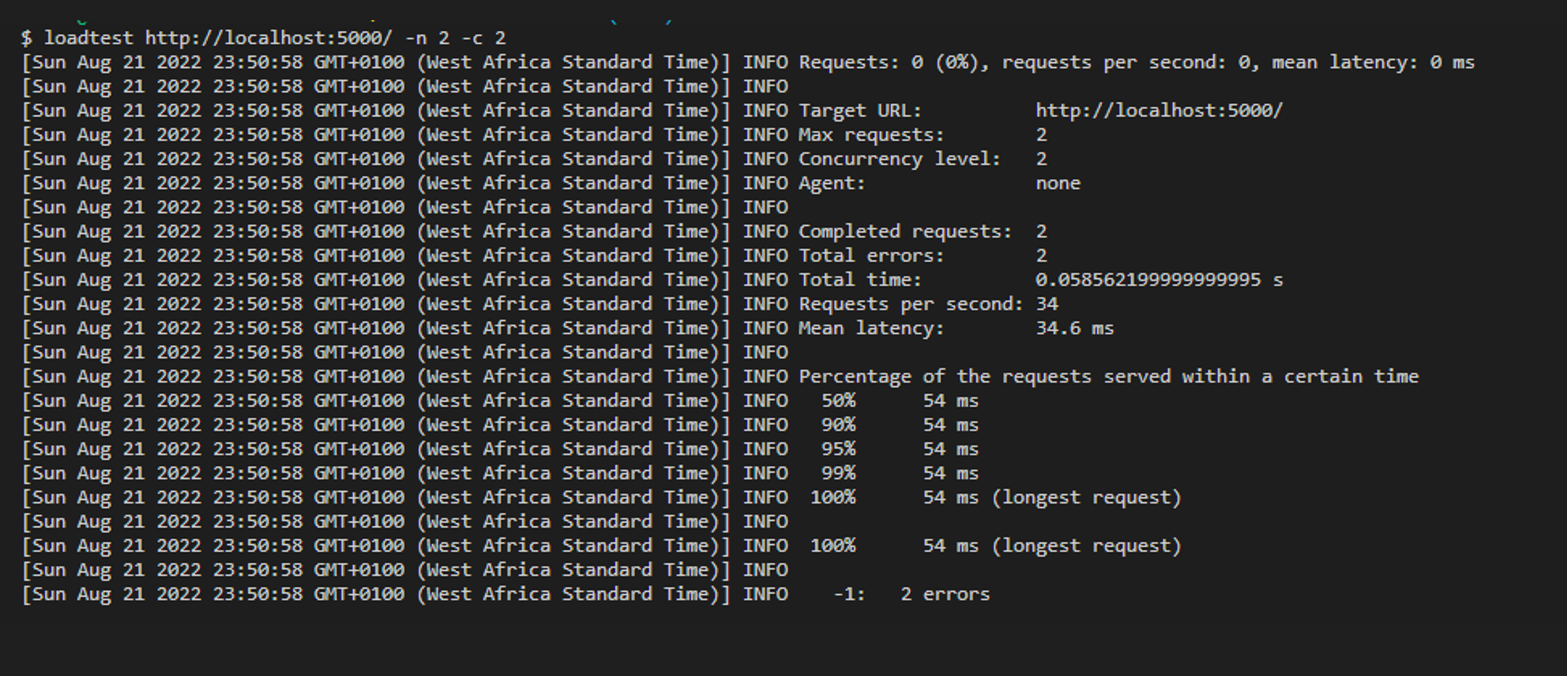
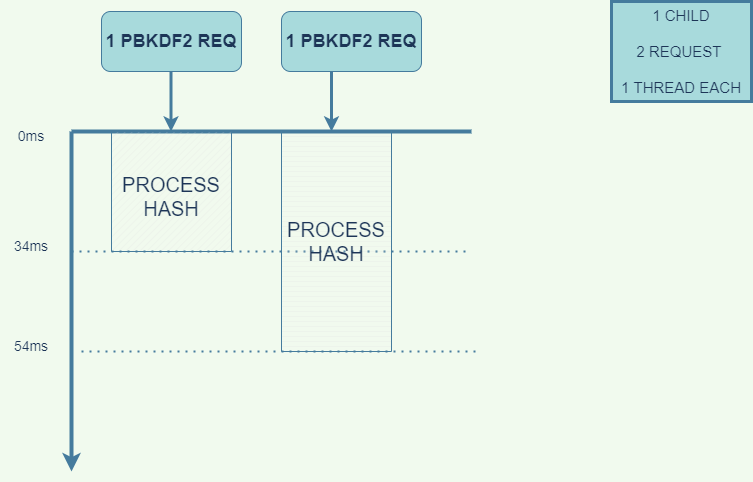
The CPU received both request at the same time, but started processing the first one before the second. The first request took 34ms to process and the later took 54ms.
This behavior is expected since we set the number of threads to one. The second request returned a response in almost 2 times the processing time of the first.
Test 3
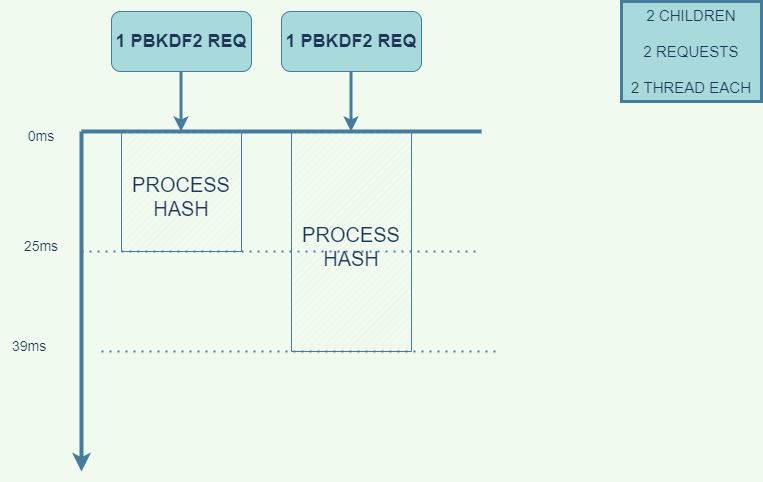
Increase the clusterCounter by 1 and run the loadtest http://localhost:5000/ -n 2 -c 2 cmd.
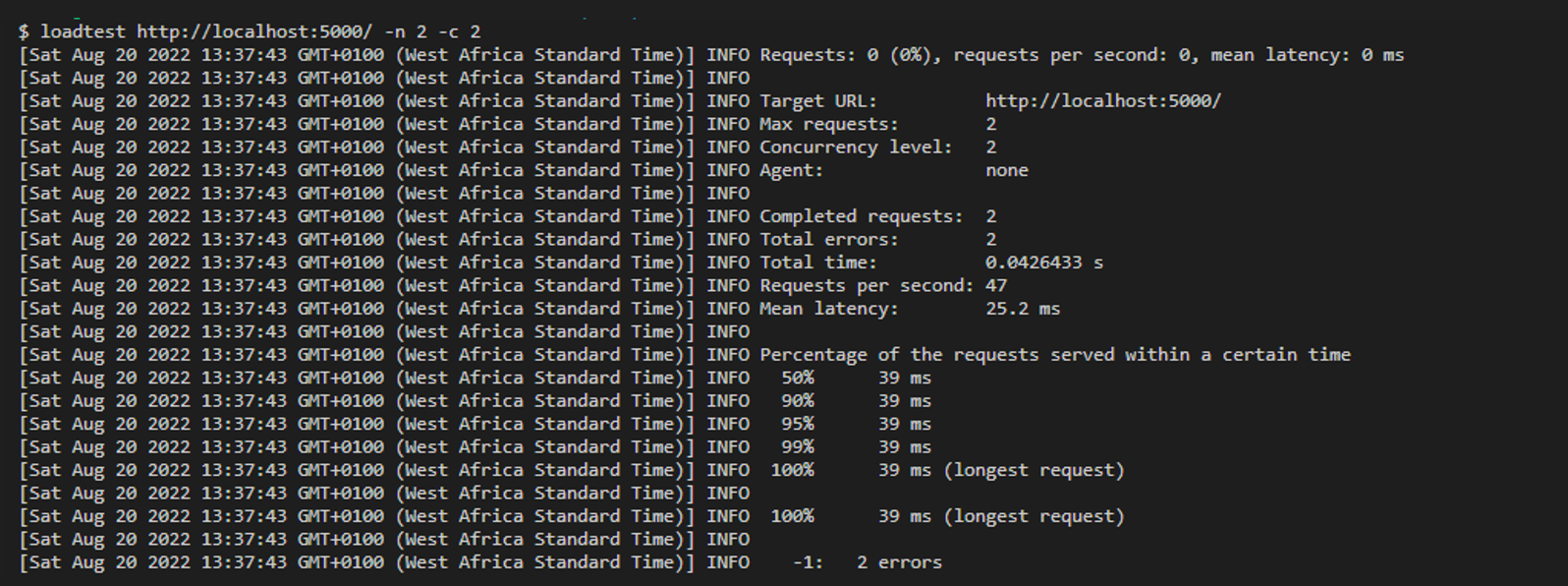
It took an average of 39ms to process requests. By slightly increasing the number of child_processes, the processing time was cut in half.
Dangers of creating more children
A node dev might be tempted to create more child process in order to increase the performance of it's application. Let's discuss why this is a bad idea.
Test 4
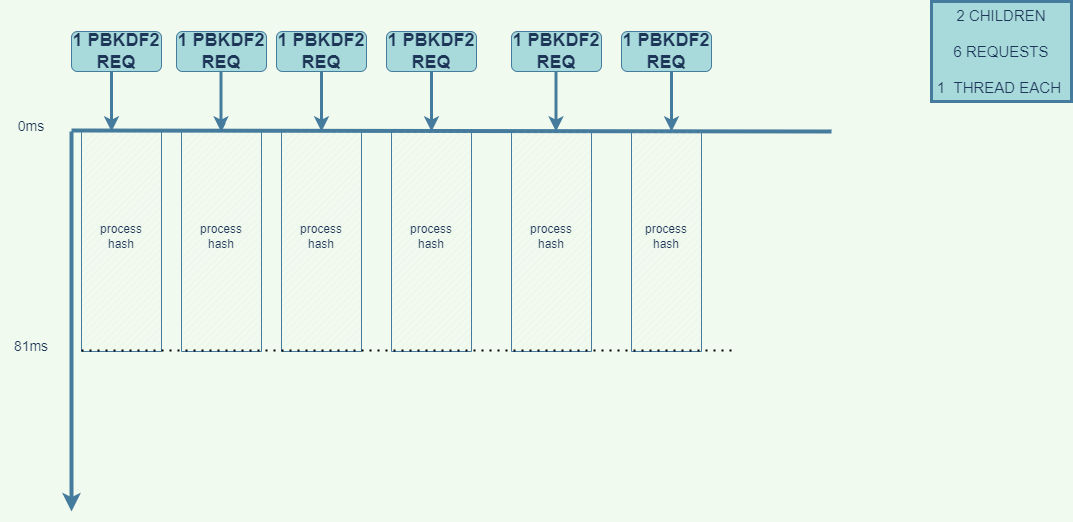
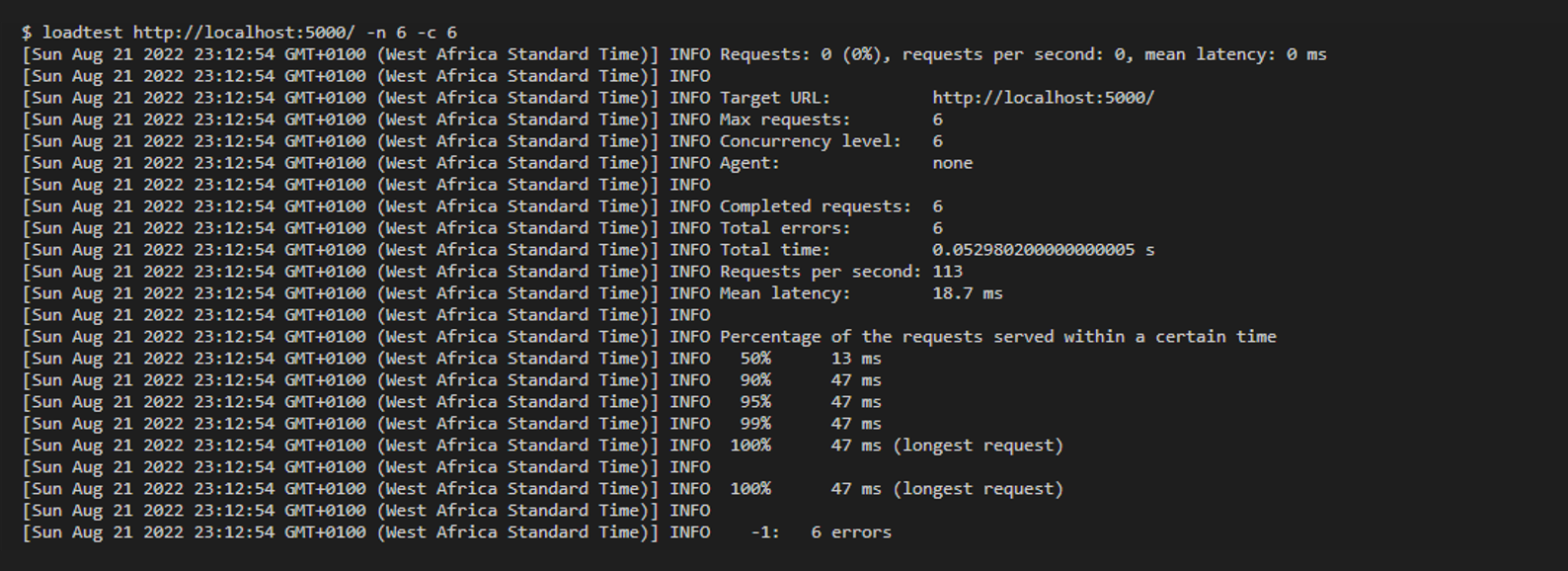
Increase the clusterCounter by 4 and run the loadtest http://localhost:5000/ -n 6 -c 6 command.
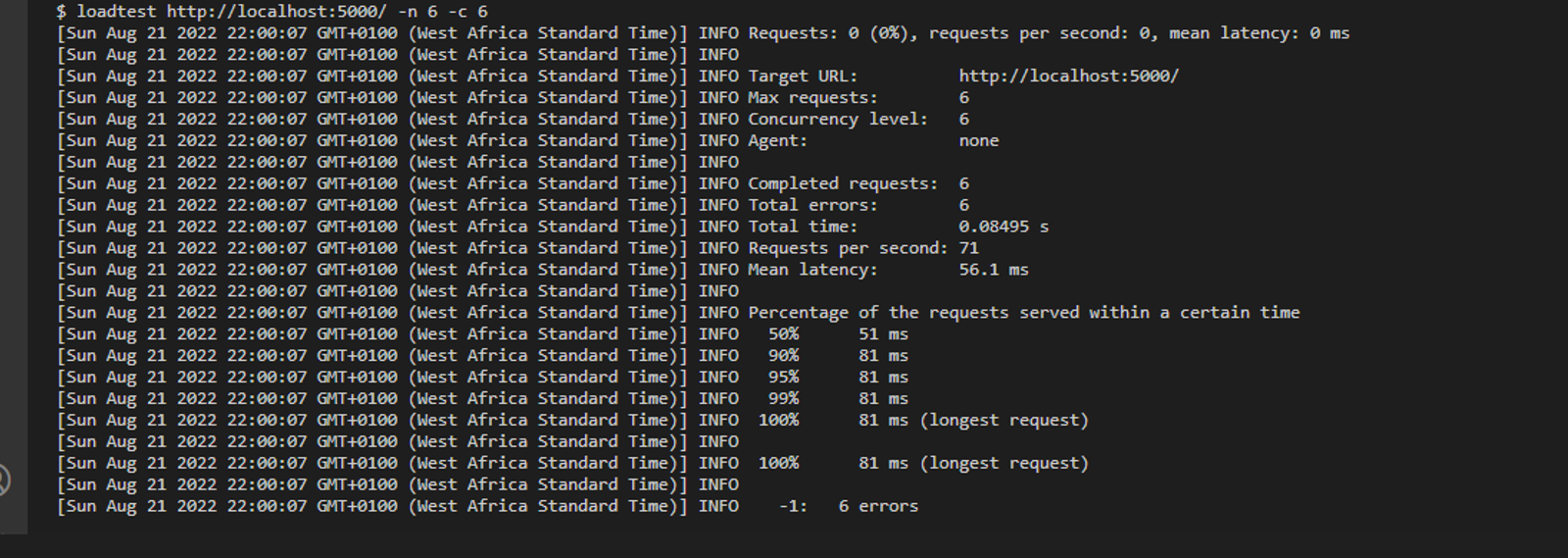
When we run the cmd, the processes take a significant longer time ( 81 ms ) to execute the hash functions. Despite the fact that we used 6 child processes. But in reality, every computer has an upper limit to the amount of data it can crunch.
Behind the scenes, each thread pick up a hash function and sends it to the CPU, The CPU is trying to process all threads at the same time. This will make our code to take a longer time before returning a result. Even though some child process returned a result quicker, the overall performance of the application suffered.
Test 5
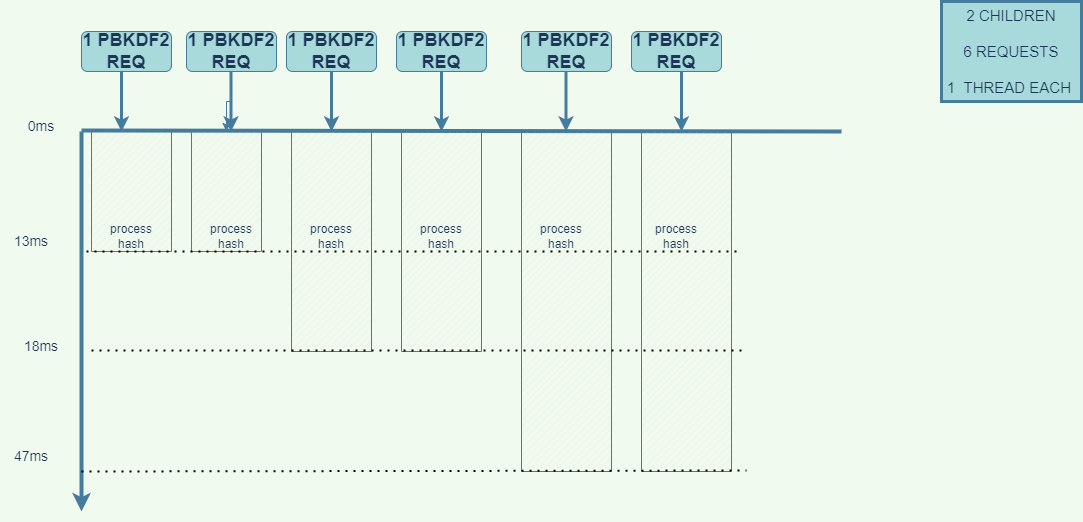
Reduce the number of counterCluster from 6 to 2. Run the same command loadtest http://localhost:5000/ -n 6 -c 6.
What happened here is, that the first two requests got the dedicated attention of the CPU cores, it processed them as fast as possible, followed by the next two and the remaining. This explains why a smaller number of child-process can process a high number of request faster than a larger number of child-process
To buttress why having a large number of child-process is not ideal. Think of a scenario where you are eating, when you stuff too much food in your mouth, it takes a longer time to chew, and swallow. Compared to when you eat moderately, it will take lesser time to chew and swallow, and in no time your mouth and throat are ready for the next spoonful.
Conclusion
In a production environment, you can use this process to benchmark your application if it would benefit from clustering. Run a series of benchmarks to test if the benefits of running your application in cluster mode are worth it.



