Enhancing node performance
This article explains how to use clustering to enhance node's performance.

My name is Ukagha Promise, I am a full-stack engineer and a technical writer. I am passionate about solving problems by building software.
Introduction
Node is a single-threaded platform that in the background makes use of the thread pool to execute asynchronous code.
When we run node index.js, node starts a single process, a single thread, and the event loop.

In multi-core systems, the process started by node will not make use of more than one core of the CPU for processing. This can slow down execution if a processing heavy task is encountered.
To take advantage of multi-core systems, Node implemented the cluster module. The cluster module helps us to run multiple copies of node that is running our server inside of them. Each spawned child has its event loop, memory, and the V8 instance.
Why use clustering?
Let's take a brief detour and discuss why clustering is key to enhancing the performance of a node application.
 A node application can run into scalability issues when a large number of users are trying to make processing-heavy requests.
A node application can run into scalability issues when a large number of users are trying to make processing-heavy requests.
Let's examine the code snippet below:
const express = require('express')
const app = express()
function startTimer(timer){
const start = Date.now()
while(Date.now() - start < timer) {}
}
// this route will delay for 5secs
app.get('/slowop', (req,res) => {
startTimer(5000)
res.send(`Processing-heavy task completed`)
})
app.get('/fastop/:name', (req,res) => {
res.send(`Your name is ${req.params.name}`)
})
const port = 5000
app.listen(port, () => console.log(`server runnning on port ${port}`))
Examining the following routes:
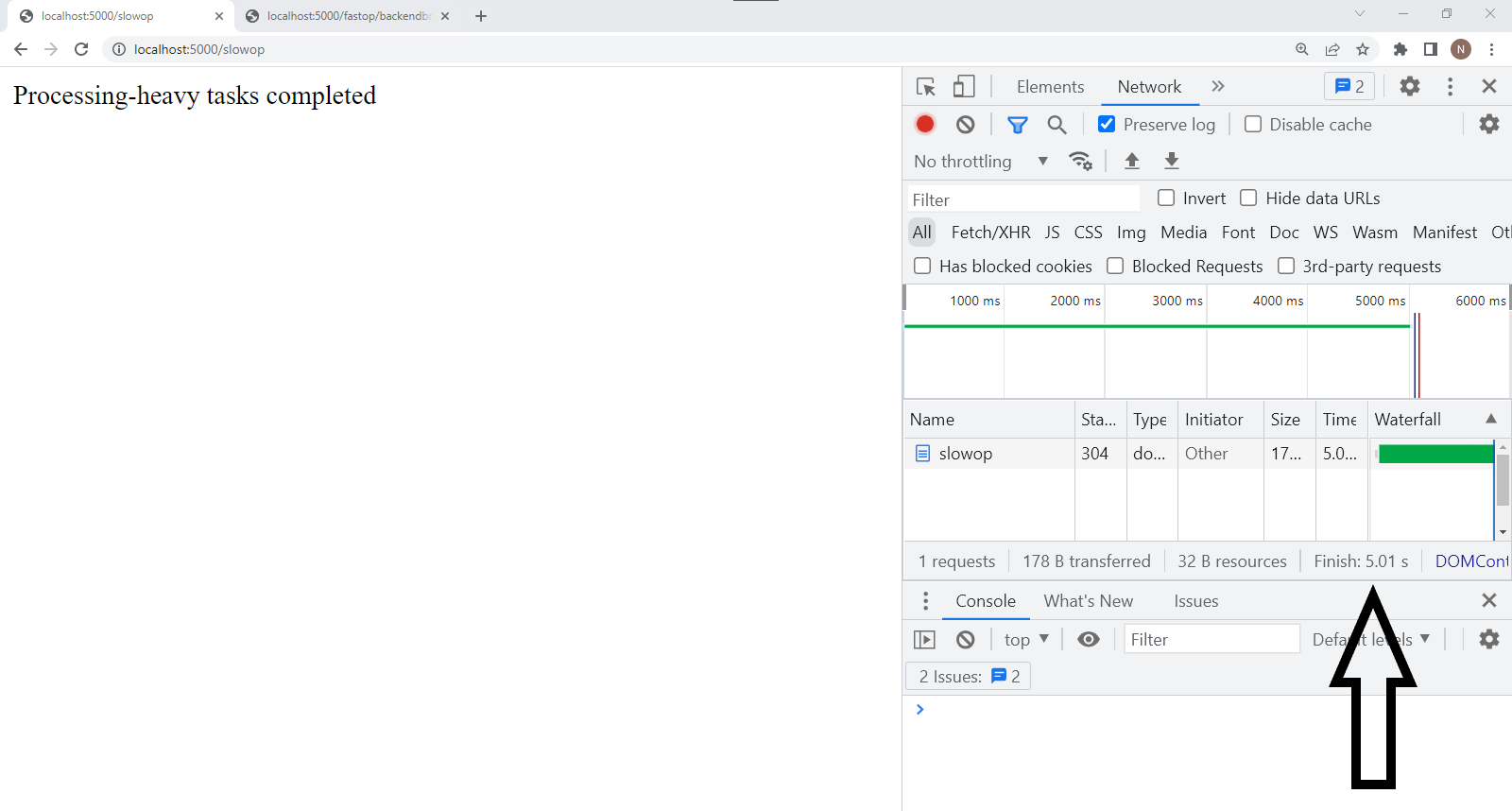
/slowop: This route took 5s to return a response.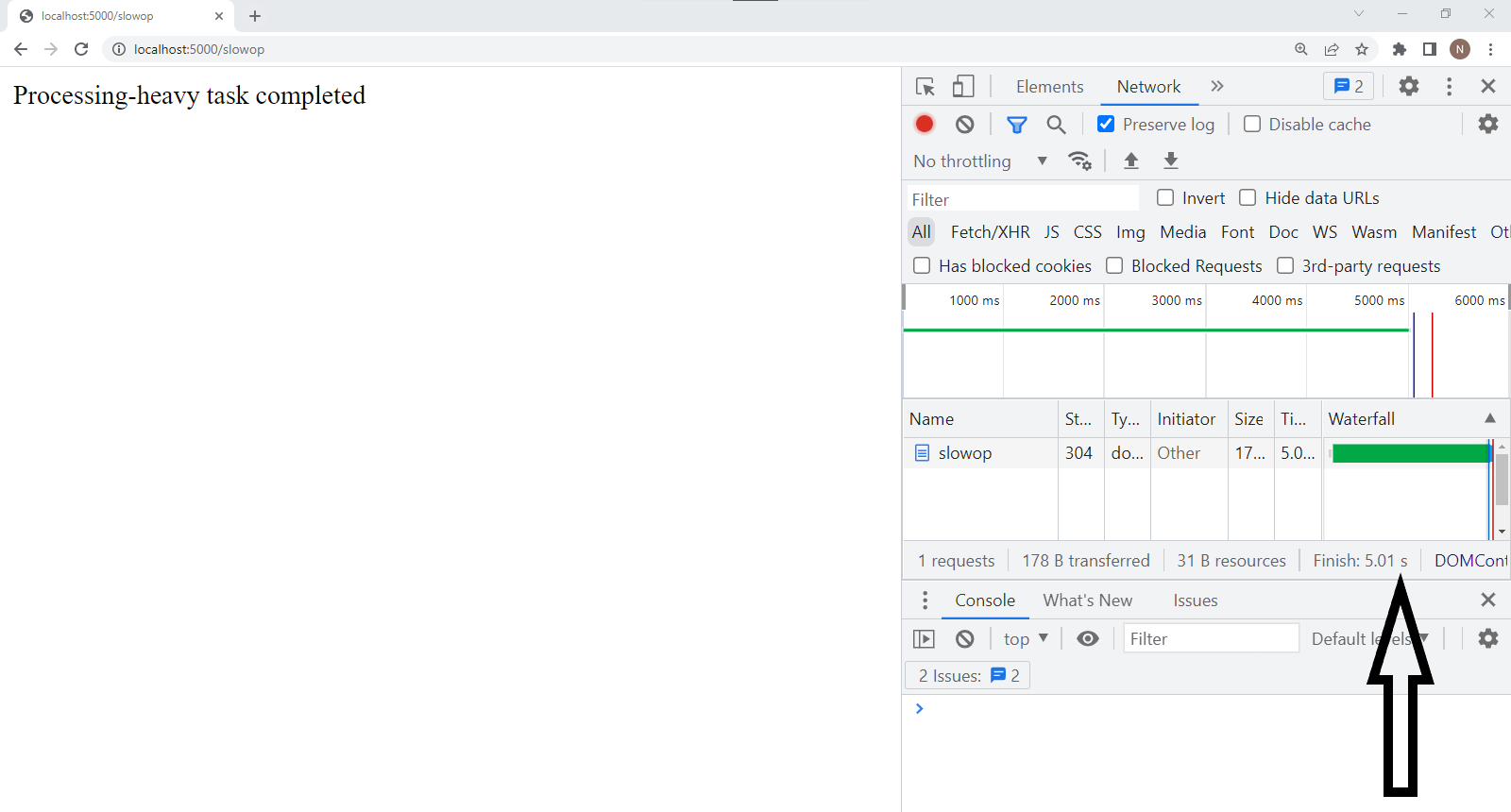
/fastop: It took this route 4.18s to return a response despite it being a lightweight request.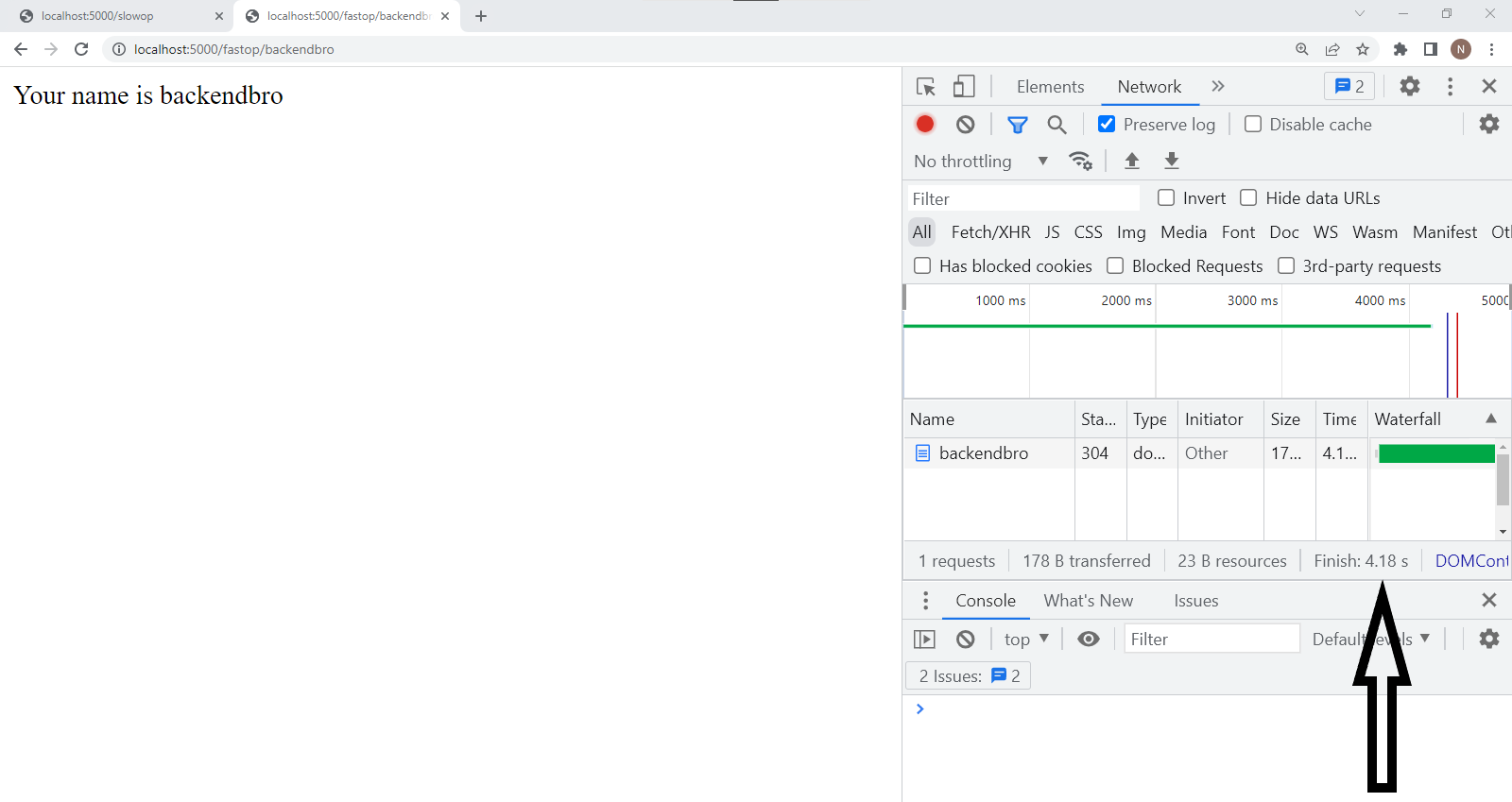
So, we can see what happens when node executes code on a single process. It tends to block operations when it encounters a heavy task. Let's analyze how clustering mitigates this problem.
Taking a deep delve into clustering
When we run our node application in clustering mode, node produces a top-level process called the cluster manager or the cluster master. The master process does not execute any code, it monitors the health of each child process. It serves an administrative purpose.
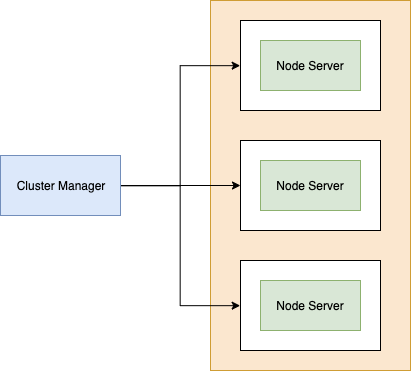
The cluster master is responsible for creating the child process using the cluster.fork() method. When we call this method, node goes back to the index.js file and executes again, thereby creating a child. The child processes use IPC (Inter-process communication) to communicate with the parent Node.js process ( master process ).
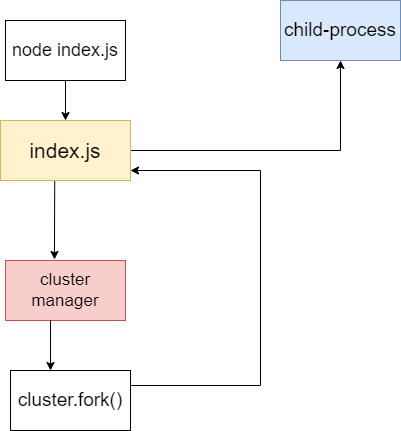
Remember, the cluster manager does not execute any of our code. We must divide our code base into two parts:
- administrative/observative
- executable
This can be done using the cluster.isMaster() method. This will return true or false
const cluster = require('cluster')
const noOfCpus = require('os').cpus().length
if(cluster.isMaster){
console.log('Hello from the cluster master')
// forking a child/worker process
for (let i = 0; i<noOfCpus; i++){
cluster.fork()
}
// watches the cluster incase of any downtime and restarts another cluster
cluster.on("exit", (worker) => {
console.log(`worker ${worker.process.pid} died`);
console.log("Let's fork another worker!");
cluster.fork();
});
}else{
console.log(`Worker ${process.pid} started`)
}
Let's examine the code snippet above:
noOfCpus: This provides us with the no of CPU cores in our OSfor loop: The for loop, will loop over thenoOfCpusand callcluster.fork()noOfCpusnumber of timescluster.on: This the event watches our processes, if any process terminates, it creates a replacementprocess.pid: This will provide a serial number of the process running
Clustering in action
Let's revisit the processing-heavy task and make requests to both routes in cluster mode.
const cluster = require('cluster')
const noOfCpu = require('os').cpus().length
if(cluster.isMaster){
console.log(`Master ${process.pid} started`)
// forking a child/worker process
for (let i = 0; i<noOfCpu; i++){
cluster.fork()
}
// watches the cluster incase of any downtime and restarts another cluster
cluster.on("exit", (worker) => {
console.log(`worker ${worker.process.pid} died`);
console.log("Let's fork another worker!");
cluster.fork();
});
}else{
const express = require('express')
const app = express()
function startTimer(timer){
const start = Date.now()
while(Date.now() - start < timer){}
}
app.get('/slowop', (req,res) => {
startTimer(5000)
res.send('Processing-heavy tasks completed')
})
app.get('/fastop/:name', (req,res) => {
res.send(`Your name is ${ req.params.name}`)
})
const port = 5000
app.listen(port, () => console.log(`port started on ${port}`))
}
/slowop
/fastop/:name
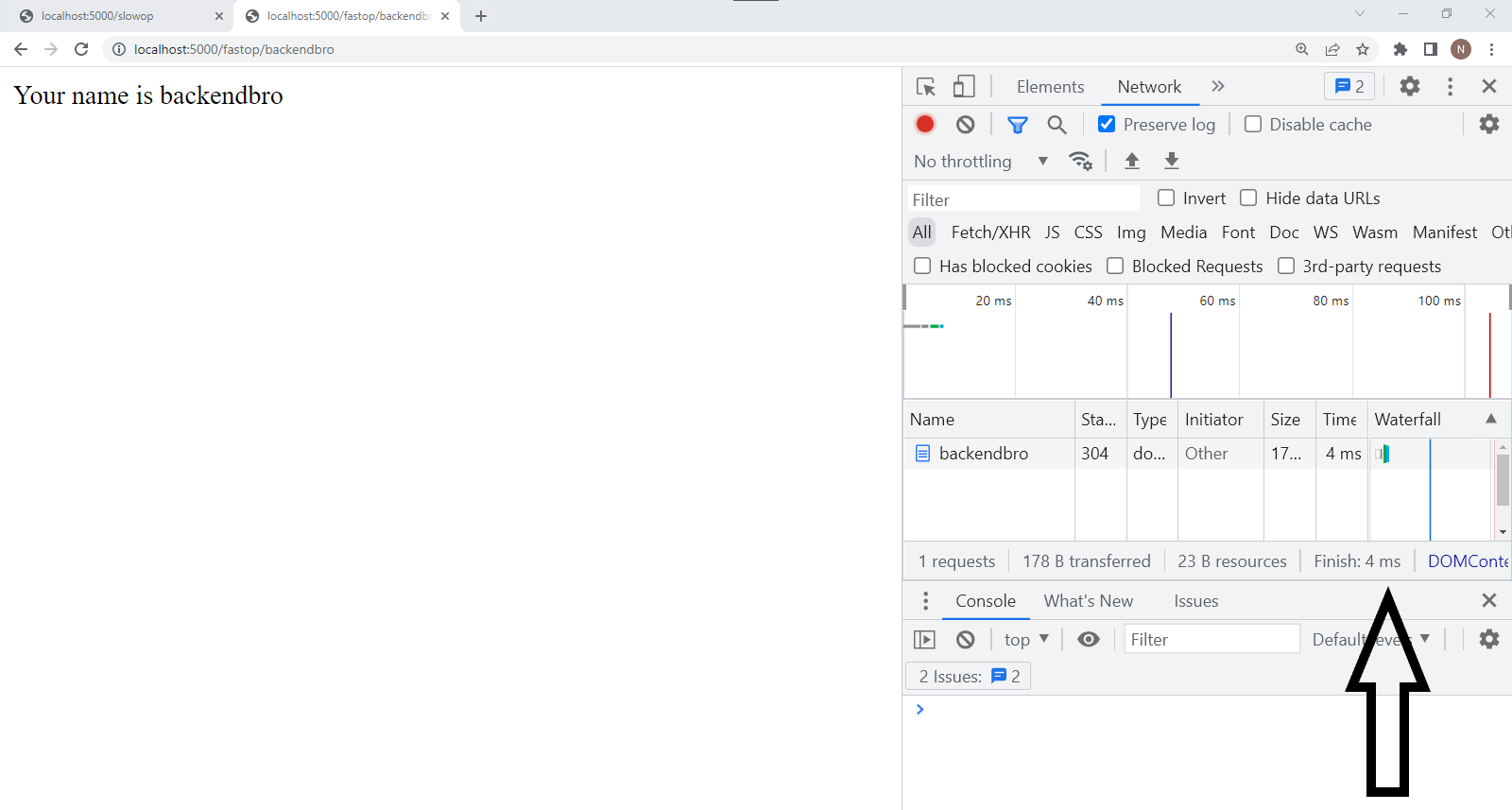
There is a significant change in the time of the second request.
This is because the /fastop/:name route was delegated to another process, there by returning a response in 4ms
pros and cons of clustering
Before you get too happy with your newfound knowledge, there are some rules involved in using clustering. A node dev might be tempted to create as many child processes as they want, after all, it enhances performance.
Here is the catch, creating too many process, will hamper the processing power of the CPU. Every CPU has a stipulated amount of data it can process at a given time. When we create more process than the number of cores of the CPU, we tend to run into latency issues. To get the most out of clustering, create process that match your number of CPU cores or lower.
Conclusion
In this article, we have learned how clustering offers a way of improving your Node.js app performance, by making use of the operating system's resources more productively and efficiently.
However, if your app isn't running a lot of ( or no ) processing-heavy tasks, then it might not be worth using clustering. Remember, each process you create has its memory, event loop, thread pool, and a V8 engine. The child process created, will need additional resources thereby causing a reduction in the performance of your application.
Before you use clustering make sure you benchmark the performance of your application in clustering mode and normal mode, before making a choice.
Read how to benchmark in cluster mode here
Credits
For more on clustering, check the cluster module documentation



